📘
Node-AIで扱える時系列データの形式
Node-AIで扱える時系列データの形式
Node-AIでモデルの学習を行うために必要な、CSVファイルの形式について解説します。
お手持ちのデータが以下のルールを満たしているかご確認ください。
プランによるアップロードの制限について
- アカウント作成後に用意される “トレーニング” チームでは公開データ以外のアップロード方法は利用できません。
- オリジナルのデータをアップロードするには新規のチームを作成し、FreeまたはBusinessプランをご利用ください。
プランの詳細は こちら
1. データの基本構成
1行目に「項目名(ヘッダー)」があり、2行目以降に「データ」が並ぶ形式にしてください。
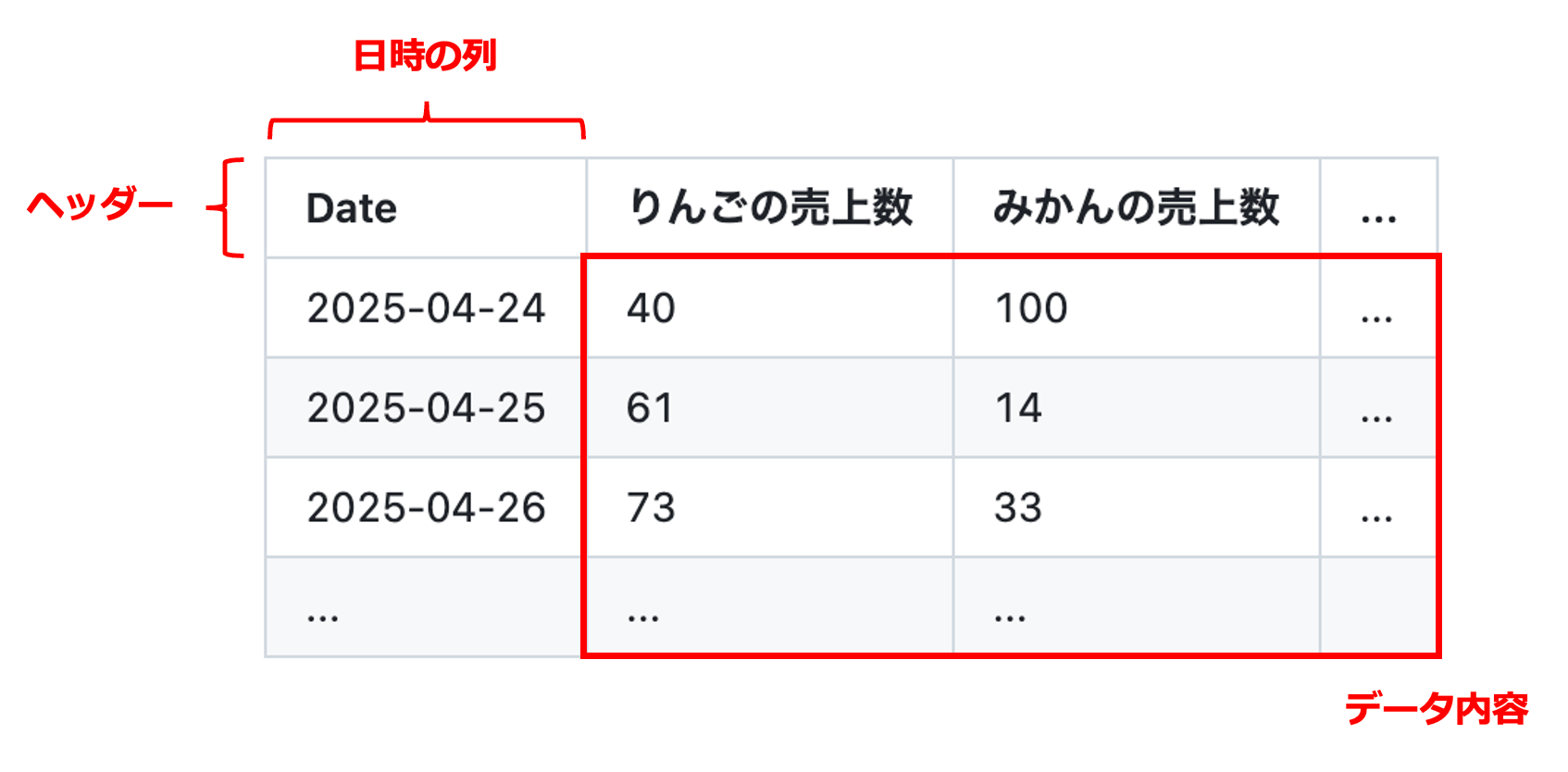
✅ 必須チェックリスト
- ファイル形式: であること(Excelファイル は不可)
- ヘッダー: 1行目に必ず項目名があること
- データ内容: 「日時」の列と、「数値」の列が含まれていること
- 行数: ヘッダーを除き、データが2行以上あること
日時の列の位置や個数について
日時の列は最低1つは含まれている必要がありますが、データの中で一番左端にある必要はありません。
また、時刻データの列が複数含まれている場合は、Node-AI 上でいずれか1つを日時の列として指定するモーダルが表示されます。
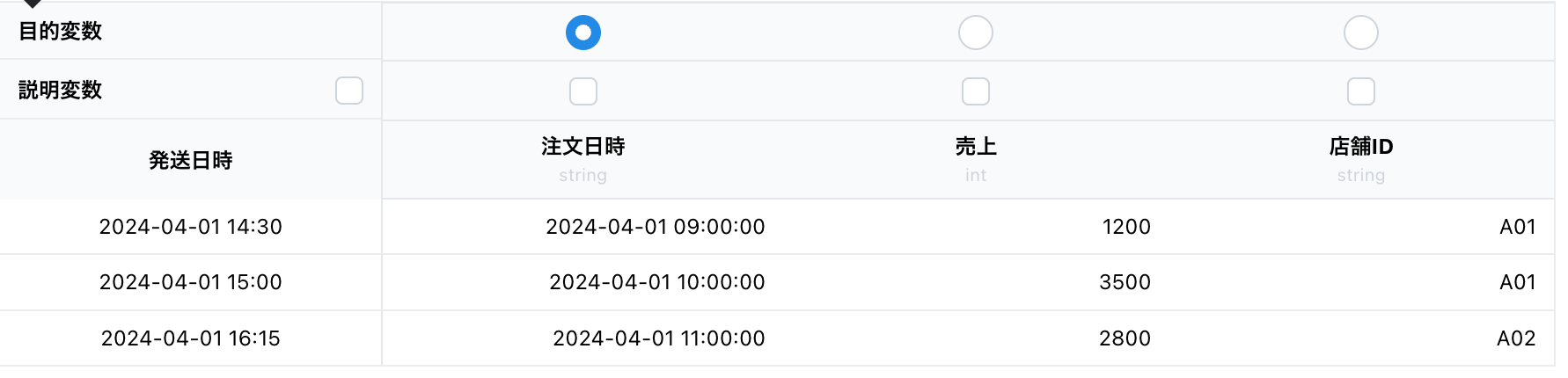
例えば、以下のようなサンプルデータを考えます。
| 注文日時 | 発送日時 | 売上 | 店舗ID |
|---|---|---|---|
| 2024-04-01 09:00:00 | 2024-04-01 14:30:00 | 1200 | A01 |
| 2024-04-01 10:00:00 | 2024-04-01 15:00:00 | 3500 | A01 |
| 2024-04-01 11:00:00 | 2024-04-01 16:15:00 | 2800 | A02 |
このデータをアップロードすると、以下のような表示になります。

右上の3点リーダーから「時刻カラムを変更」メニューをクリックすると、「時刻カラムを選択」モーダルが表示されます。

ここで、例えば「発送日時」を選択して保存すると、Node-AI上では「発送日時」が日時の列として、「注文日時」がデータ内容として扱われることになります。
2. 日時のフォーマット
Node-AIが自動で認識できる日時の形式は以下の通りです。
| 時刻形式 | 例 |
|---|---|
| 2021-01-23 | |
| 2021/01/23 11:22 | |
| 2021.01.23 11:22:33.000 UTC | |
| 2021-01-23T11:22:33Z | |
| 20210123T112233+0900 |
※ などの和暦や、 のような日本語形式、 のような年を含まない形式は利用できません。
うまくいかない時は?
アップロード時にエラーが出る場合や、読み込みが止まってしまう場合は、以下のトラブルシューティングをご覧ください。
学習用データと予測用データの違い
上記のCSVフォーマットは共通ですが、「これからモデルを作る(学習)」場合と、「未来を予測する(推論)」場合では、用意すべきデータの期間や列のルールが少し異なります。
- 学習用: 目的変数(正解)が必須です。
- 予測用: 目的変数は不要ですが、直近のデータ(窓幅分)が必要です。
予測カード等で利用するデータを作成する際は、以下のガイドを必ずご確認ください。